
こんにちは、アイスリーデザインのマーケティング部の田中です。
今回は、画像生成、言語生成といった様々なAIの性能を上げることができる「特徴量エンジニアリング」について、エンジニアではない人にもわかりやすいよう、初心者向けに解説させていただきます。
特徴量エンジニアリングは、機械学習モデルの性能を最大限に引き出すための重要なデータ加工プロセスです。機械学習プロジェクトの成功は、使用されるアルゴリズムだけでなく、そのアルゴリズムに供給されるデータの質に大きく依存します。特徴量エンジニアリングでは、「特徴量」と呼ばれる、データの個々の属性や変数を適切に加工し、モデル(※)が最も効果的に学習できる形に整えることを目指します。
(※)モデルとは?
機械学習において、入力データに対して結果(=出力)を導き出す仕組みのことをさします。そのため、Googleによって開発されたGeminiもモデルであり、ChatGPTも1つのモデルです。ただし、GeminiやChatGPTなどといったモデルは既に出来上がっているモデルのため、私たちが特徴量エンジニアリングを行うことはできません。あくまで、出来上がっていないモデルに対して、効果的に学習できる形へと整えていく手法です。
Netflixのレコメンド機能やGoogleの検索エンジンも特徴量エンジニアリングがなされて出来上がっています。特徴量エンジニアリングはこのような、モデルがさらに精度の高い結果を出力できるように、整えていくプロセスになります。
ここまで、少し難しい書き方になりましたが、アンケートでイメージするとわかりやすいかもしれません。
アンケートを収集したとき、アンケートにはよく任意入力項目も設定されていると思います。任意入力項目は、任意であることもあって、入力されない方も多いですが、それがエクセルなどで集計されたときにブランク(すなわち、データがない箇所)になってしまいます。「このデータがない箇所ってどう扱うの?」というのを調整するのが特徴量エンジニアリングの1つです。それがエクセルの場合、列項目を削除してしまうのか、そのブランクにほかの妥当な数字をあてこむのか、これは人間が判断しなければいけません。扱い方について、人間が判断できていないものを、機械でそのまま処理できるわけがありません。
「こういう風に処理してくださいね」ということを人間が明確にし、機械でも読みやすいようにするのが特徴量エンジニアリングです。
この記事では、特徴量エンジニアリングの重要性や具体的な手法、機械学習全体における役割について詳しく解説します。
そもそも機械学習とは何か
特徴量エンジニアリングを理解するためには、まず「機械学習」が何かを押さえておく必要があります。機械学習とは、データを基にパターンや法則を学び、それを用いて新しいデータに対する予測や判断を行う技術です。たとえば、過去の売上データから将来の売上を予測したり、画像を識別したりすることができます。機械学習アルゴリズムは、大量のデータを解析し、そのデータから自動的に学習することによって、高精度の予測を実現します。しかし、どれだけ優れたアルゴリズムであっても、提供されるデータが適切でなければ、満足のいく結果を得ることはできません。ここで、データの「質」を向上させるためのプロセスである「特徴量エンジニアリング」が重要になってきます。
特徴量エンジニアリングの定義とプロセス
特徴量エンジニアリングとは、機械学習モデルの予測精度を高めるために、データの特徴量を検討し、加工するプロセスを指します。
このプロセスには、以下のような作業が含まれます。
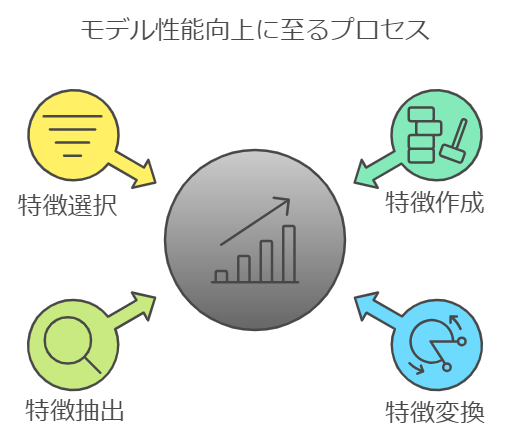
- 特徴作成:新しい特徴量を生成します。
生年月日のようなただの数字の羅列も、そこから現在の日付と紐づけて、年齢を算出することができます。
例えば、とある健康食品の購入者の誕生日だけを知っていたとしても、それだけでは数字の羅列だけでは何の分析も掛けることができません。しかし、購入当時の日付がわかれば、誕生日と紐づけることで年齢がわかるようになります。すなわち、ただの数字に過ぎなかったものを特徴量へと進化させる、つまり特徴量を生成するということにあたります。
この特徴量を生み出すという動きによって、どういった年齢層がその商品を買うのかターゲット層を絞ることができるようになります。
(「あれ、これは特徴量の変換ではないのか?」と思われた方もいらっしゃるかもしれません。しかし、これは元のデータは特徴量ではないため、あくまで特徴量生成に該当します。) - 特徴変換:既存の特徴量を別の形に変換します。
数値データのスケーリングとカテゴリデータのエンコーディング等といったことが含まれます。数値データのスケーリングというのは、異なる範囲や単位を持つ特徴量を共通の尺度に変換することを指します。数字の大きさが様々だと、1種類の特徴量があまりに大きな影響を与えてしまって、ほかの特徴量の効果が薄くなってしまう可能性があります。それを共通の尺度にすることで、影響力の差を大きくさせないようにするという目的があります。
また、カテゴリデータのエンコーディングは、数値形式ではないデータ(例えば、色など)を数値形式に変換するプロセスです。機械学習をする上で、数値形式になると、わかりやすくなります。 - 特徴抽出:高次元データ(※)から有用な情報を抽出し変換するプロセスを指します。
主成分分析(PCA)などの分析手法を使って、データの次元を削減していきます。それにより、データの複雑さを削減したり、ノイズの除去や計算効率の向上を図ることができます。
(※)高次元データとは?
高次元データには、画像データ、センサーデータ、ECの購買履歴データなど、世の中にある様々なデータが該当します。
例えば、画像データでいえば、各ピクセルの色情報を特徴量として扱うため、例えば1000px×800pxの画像であれば、それに光の三原色であるRGBカラー(赤、緑、青)の3つをかけた結果が次元数になります。つまり、1,000×800×3=2,400,000、240万次元のデータとなります。
このように、あまりにデータの情報が豊富なため、データの分析、機械学習モデルの構築が困難になってしまう可能性があるため、この情報から特徴を抽出させる必要があります。
- 特徴選択:多くの特徴量の中から、モデルの精度に貢献するものを選び出します。不要な特徴量を除外することで、モデルの過学習を防ぎ、計算効率を向上させます。先ほど高次元データで解説した画像データを分類する場合、240万次元のデータを扱うことになりますが、ここで、エッジ検出(物体の輪郭を特定する技術)や色彩情報など、重要な特徴のみを抽出することで処理すべきデータ量が大幅に削減され、学習の高速化につながります。
これらのプロセスを通じて、モデルに適したデータが準備され、予測精度が大幅に向上します。また、不要なデータを取り除くことで、計算資源の節約にもつながり、効率的なモデル構築が可能になります。
例えば、カフェを運営していて、「どういったメニューがいつ需要があるのかを予測したい」と考えるとします。その場合、カレンダーだけあっても、ただの日付という数字データでしかないですよね。そのカレンダーにおいて、休日が明確になっていて、売上データがリンクされていれば、休日に売上が高いのか、平日に売上が高いのかがわかり、そのカフェに訪れる人は「働いている人が多い」のか、「休日のお休みに使う人が多いのか」といったことがわかるようになると思います。このように特徴量を組み合わせることで、予測の精度、モデルの性能を向上させることができるのです。

機械学習における特徴量エンジニアリングの役割
機械学習モデルは、データからパターンを学び、それを基に予測を行います。しかし、データが不適切な形で提供されると、アルゴリズムの性能が大きく損なわれることになります。このように、機械学習において特徴量エンジニアリングは欠かせないものとなります。この特徴量エンジニアリングを改めて、役割として整理すると下記の3点にまとめられます。
- データの質の向上:特徴量エンジニアリングによって、アルゴリズムがデータから学びやすくなり、精度の高いモデルが構築されます。
- バイアスの軽減:適切な特徴量を選定し、適切に変換することで、モデルが特定のバイアスに引きずられるのを防ぎます。
- 学習効率の向上:高次元データの次元削減や不要な特徴量の削除により、学習速度が向上し、計算資源の節約にもつながります。
特徴量エンジニアリングを実施することで発生するコスト
特徴量エンジニアリングを行っていくうえでのコスト(ここでいうコストは「労力」を意味します)は、データの規模や複雑さ、使用する技術により異なります。
- データ準備のコスト:データの収集、クリーニング、加工には多くのリソースが必要です。
- ツールと技術の導入コスト:特徴量エンジニアリングには、特定のツールやソフトウェアが必要であり、その導入や維持に費用がかかります。
- 人的リソースのコスト:特徴量エンジニアリングは専門的な知識が要求されるため、経験豊富なデータサイエンティストの投入が必要です。
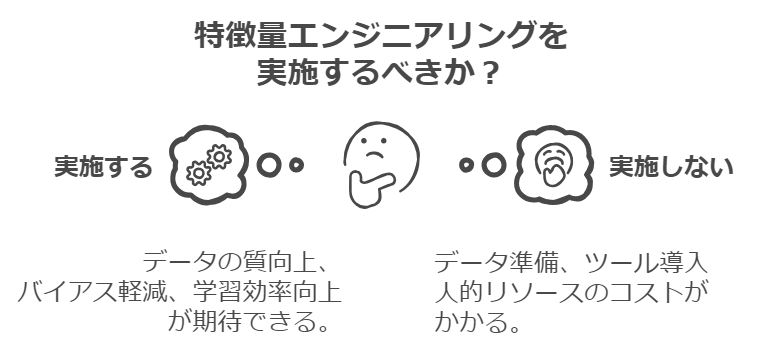
特徴量エンジニアリングに費やしたコストは、モデルの性能向上に直接的に寄与し、結果としてビジネスのROIを高めることへと繋がる可能性があります。
特徴量エンジニアリングとファインチューニングの違い
AIのモデリングにおける調整という文脈で、「ファインチューニング」という言葉を目にされた方も少なくないのではないでしょうか?
では、このファインチューニングとはどういった意味合いなのか、特徴量エンジニアリングとは何が違うのかを見ていきたいと思います。
ファインチューニングとは
既に訓練されたモデルを特定のタスクやデータセットに合わせて調整するプロセスを指します。OpenAI社のChatGPTのような大規模言語モデル(LLM)等を使用する時に非常に有益です。ファインチューニングでは、限られたデータセット(つまり少ないデータ量)を使用してモデルを再訓練することが可能です。既にモデルが大量のデータを学習しているので、データが限られていても有効に機能するということです。
特徴量エンジニアリングが、モデルの性能を上げることを目的としたプロセスであるのに対し、既に出来上がっているモデルを調整するのがファインチューニングとなります。どちらも機械学習におけるプロセスの1つでありますが、先述の通り目的と実施するタイミングが異なります。
ファインチューニングと似たようなアプローチ手法の1つとして、RAG(Retrieval Augmented Generation:検索拡張生成)があります。RAGの場合は、社内外のデータソースから情報を検索するものであり、その検索にLLMの文章生成能力を流用します。RAGは、LLMの機能不足を補います。
RAGも含め、AIのモデリングにおいて色々な言葉が増えていますが、それぞれAIモデルに対して、性能を良くするためのアプローチ方法である、そしてそのアプローチは色々なフェーズで実施することが可能であると認識して頂くのが良いのではないかと考えております。
代表的なサービス比較
特徴量エンジニアリングをサポートするツールやサービスは、機械学習プロジェクトの効率と効果を大きく左右します。ここでは、代表的なサービスについて、特徴量エンジニアリングの観点から詳しく比較します。
1. Pythonライブラリ(Pandas、Scikit-learn)
概要:
機械学習やデータサイエンスの分野で広く使用されている言語であるPython。Pythonにはライブラリという、難しいコードを書かずとも、簡単なコードで処理できるようにしてくれる、様々な便利機能が詰まっているものが存在します。特徴量エンジニアリングに活用できるライブラリがいくつかあり、有名なのは、PandasやScikit-learnです。Pandasはデータの操作と分析に特化しており、Scikit-learnは機械学習のモデル構築と評価を行うためのツールです。
特徴量エンジニアリングの機能:
- 柔軟性:Pandasを使用すれば、特徴量を簡単に作成、変換、集約できます。カスタム関数を用いて、複雑な特徴量を生成することも可能です。
- 標準化された処理:Scikit-learnには、特徴量のスケーリングやエンコーディング、欠損値の補完など、一般的な前処理を行うためのユーティリティが豊富に用意されています。
- 特徴選択:Scikit-learnは、相関性や統計的手法に基づいた特徴選択アルゴリズムを提供しており、無駄な特徴量を削減することができます。
2. クラウドサービス(AWS SageMaker, Google Cloud AutoML)
概要:
AWS SageMakerやGoogle Cloud AutoMLは、クラウドベースの機械学習サービスです。どちらも機械学習の専門知識がなくとも、簡単にモデルを構築することができるよう設計されています。特徴量エンジニアリングからモデルのトレーニング、デプロイまでの一連のプロセスをサポートします。これらのサービスは、初心者から上級者まで幅広いユーザーに向けて設計されています。
特徴量エンジニアリングの機能:
- 自動特徴量エンジニアリング機能搭載:どちらもデータから自動的に特徴量を生成する機能を備えています。AWS SageMaker Canvasでは「自動特徴量エンジニアリング」機能があり、Google Cloud AutoMLも同様の機能を備えています。
- 様々なデータソースからの取り込みが可能:様々なソース(ストリーミングデータ、バッチデータ、データ準備ツールなど)からデータを取り組む機能を搭載しています。
- スケーラビリティが高い:クラウド上での処理により、大規模データセットの処理やモデルのトレーニングが迅速に行えます。
3. 商用ソフトウェア(DataRobot, H2O.ai)
概要:
DataRobotやH2O.aiは、どちらも自動機械学習のプラットフォームとして知られています。これらのプラットフォームは、機械学習の全プロセスを簡素化し、迅速にビジネス価値を提供することを目的としています。
特徴量エンジニアリングの機能:
- 自動化とカスタマイズ:自動化された特徴量生成機能と、カスタム特徴量エンジニアリングの両方がサポートされています。ユーザーは自動生成された特徴量を確認し、さらに改良を加えることができます。
- 高度なアルゴリズム:特徴量選択や次元削減のための高度なアルゴリズムが組み込まれており、データの質を大幅に向上させることが可能です。
- ビジネス向けのインサイト提供:機械学習モデルの解釈性を高める機能があり、特徴量の重要度やモデルの決定要因を視覚化することができます。
各ツールやサービスには、それぞれ強みと弱みがあり、利用するケースやニーズによって最適な選択が異なります。小規模なプロジェクトやカスタマイズが求められる場合には、Pythonライブラリが適しているでしょう。一方、大規模データや迅速なモデル開発が求められる場合には、クラウドサービスや商用ソフトウェアの利用が効果的です。また、クラウドサービスは、AWSやGoogle Cloudと連携しているため、どういった環境でアプリケーションを開発するかによって、特徴量エンジニアリングをどのツールを使って行うのかを検討してもよいでしょう。競合するサービスの特徴を理解し、プロジェクトの特性やリソースに応じて最適な選択を行うことが、成功の鍵となります。
まとめ
特徴量エンジニアリングは、機械学習において重要な役割を果たします。特徴量エンジニアリングを適切に行うことで、AIモデルの学習効率が向上し、必要なリソースだけを使うことに専念できるようになり、トータルのコスト削減に繋がります。
アイスリーデザインでは、特徴量エンジニアリングも含めたAI、機械学習を活用したアプリケーションやシステム構築のお手伝いも行っています。特徴量エンジニアリングを用いた技術開発に関しては、先日プレスリリースも配信させていただきましたので、是非ご覧ください。今回の技術開発により、一般的な大規模言語モデル(LLM)と比較して、さらに出力データの精度を向上させることに成功しました。
色々読んでみたけど、さらに特徴量エンジニアリングを用いて精度の高いAIを活用したアプリケーションやシステムを構築したい、またはそもそも今開発したいものをAIによってさらに進化させることができるのかどうかを相談してみたいといった方は、ぜひ私たちにご相談ください。

















