こんにちは、アイスリーデザイン、マーケティング部の田中です。
本記事のタイトルにある「LLM」という言葉、最近どこかで耳にした覚えがある人も少なからずいらっしゃると思います。
この言葉を目にするようになったきっかけはChatGPTです。
2023年の新語・流行語大賞にもノミネートされたChatGPT。短期間で爆発的に知名度が上がり、現在の生成AIブームの火付け役となりました。
OpenAI社により、ChatGPTが発表されたのは、2022年11月。この時から、AIビジネスが激増し、企業はAIへの対応に追われ、雇用が変わり、教育現場が変わりました。生成AIの登場により、世界はAIを中心に大きな変化が起こっており、まさに1つの産業革命が起きていると言っても過言ではないと思います。そして、今も尚、この革命の最中にあります。このような革命の中心である、ChatGPTの基盤となる技術は何か、というときに出てくるのが、タイトルにもあるLLM(大規模言語モデル)です。
今回はこのLLM及びLMについて、そして、各社がオリジナルでつくっていくべきとも言われているSLM(小規模言語モデル)とは一体どういったものなのか。そして簡単にNotebookLMの使い方について、詳しく解説していきます。
LLMが急成長した理由:技術の進化とデータの爆発
まず、なぜそもそもChatGPTが今生み出されたのでしょうか?
それはLLMが急成長を遂げたということが背景にあり、その成長の理由としては技術の進化とデータの爆発的な増加が挙げられます。
技術の進化
AI言語モデルの進化は、主にディープラーニング技術の発展と、それを支える計算資源の進化によるものです。
以前は、自然言語を扱うAIはRNN(リカレントニューラルネットワーク)やLSTM(長短期記憶ネットワーク)といったアーキテクチャが主流でしたが、2017年に登場したTransformerアーキテクチャが、言語モデルの性能を飛躍的に向上させました。
今、出てきた「RNN」「LSTM」「Transformerアーキテクチャ」とは、いったいどのようなものなのでしょうか?一つひとつ見ていきたいと思います。
RNN(Recurent Network)は、1980年代に概念が誕生していた、文章解析・生成(自然言語処理)に適したモデルです。しかし、このRNNには、長期的な記憶を持てないという課題があり、その課題を解決したのが、LSTM(Long Short Term Memory)です。長期的な記憶を持てないということは、桃太郎の話をしていたら、突然脈絡なく桃太郎が女性になってしまったり、主人公が一寸法師になってしまう可能性があるということです。
このように文章生成において長期的な記憶を持たないと、訳のわからないことになってしまいかねません。そのため、LSTMによる解決は画期的でした。一方で、LSTMでは計算コストの増大が膨らみ、逐次処理のため、学習速度も早さが見込めませんでした。すなわち、一般の方が利用できるような状態ではなかったということです。この問題点を解決したのがTransformerです。
Transformerは、2017年6月に、Googleの研究チームによって発表されたモデルです。LSTMよりも長い文脈の理解が可能になり、並列処理も可能なため、計算効率も高くなりました。他にも、モデルを大きくしても学習可能な特徴を持つなど、ほかのモデルと比べて優れている要素が多く、現在の大規模言語モデルの基盤となる重要な技術となったのです。
ChatGPTやGoogleのGeminiなど数々の生成AIもまた、Transformerアーキテクチャが基盤にあり、この技術は、以前のモデルよりも大量のデータを効率的に処理し、テキストの意味をより深く理解できるように設計されています。
加えて、GPUやTPUといった高速な計算装置の進化も、モデルの規模を大きくすることを可能にしました。これにより、以前では処理できなかったような膨大なデータ量を扱えるようになり、LLMの開発が加速しました。
LLMの説明をすると通らずにはいられない言葉である、GPUとTPUについても解説いたします。
GPUとは、グラフィックス処理ユニット(Graphics Processing Unit)の略称で、コンピューターのグラフィックス処理を高速化するために設計された専用プロセッサのことを指します。Transformerの注釈に合った通り、Transformerは並列処理を行うのですが、このGPUは並列処理に特化した設計がされています。
似たような単語として、CPUという言葉を聞かれた方もいらっしゃるかと思いますが、CPUはコンピュータの頭脳や司令塔と呼ばれ、プログラムの命令を解読し実行する、コンピュータの中核となる重要部品です。並列処理の反対である逐次処理(タスクを順に処理していく)に適しているのがCPUです。大量のデータを同時に処理をする場合は、GPUが最適です。
TPU (Tensor Processing Unit) は、Google が開発した機械学習に特化したカスタムプロセッサです。基本的にはGoogle Cloud Platform上でサービスとして提供されています。深層学習を高速化させるプロセッサで様々な大規模なAIモデルのトレーニングに向いています。
機械学習において、GPUもTPUも切っては切り離せないものとなっています。
データの爆発的増加
さらに、インターネットの普及により、利用可能なテキストデータが飛躍的に増加しました。ソーシャルメディア、ブログ、ニュースサイト、学術論文など、インターネット上には膨大な量のテキストデータが存在しており、これを活用することでAIはより多くの知識を学習することができます。特に、企業や研究機関では、特定の業務に関連するデータを使ってLLMを訓練し、業務効率の向上やコスト削減に役立てることが可能です。
言語モデル(LM)の概要:LM、LLM、SLMの基本的な違い
言語モデル(LM)とは、テキストデータからパターンやルールを学び、自然言語を理解し、生成するためのアルゴリズムのことを指します。LMには、大きく分けて3つのモデルがあります:LM、LLM、そしてSLMです。
LM(Language Model/言語モデル)
LMは、テキストデータを基に、単語や文章の関係性を理解・予測するために使用されるモデルの総称です。つまり、LLMもSLMもLMです。
基本的なものとしては、単語間の共起頻度を基にしたモデルや、より複雑なニューラルネットワークを使ったものがあります。
ニューラルネットワークとは、人間の脳内にある神経細胞(ニューロン)とそのつながり(シナプス)を数式的なモデルで模したものです。
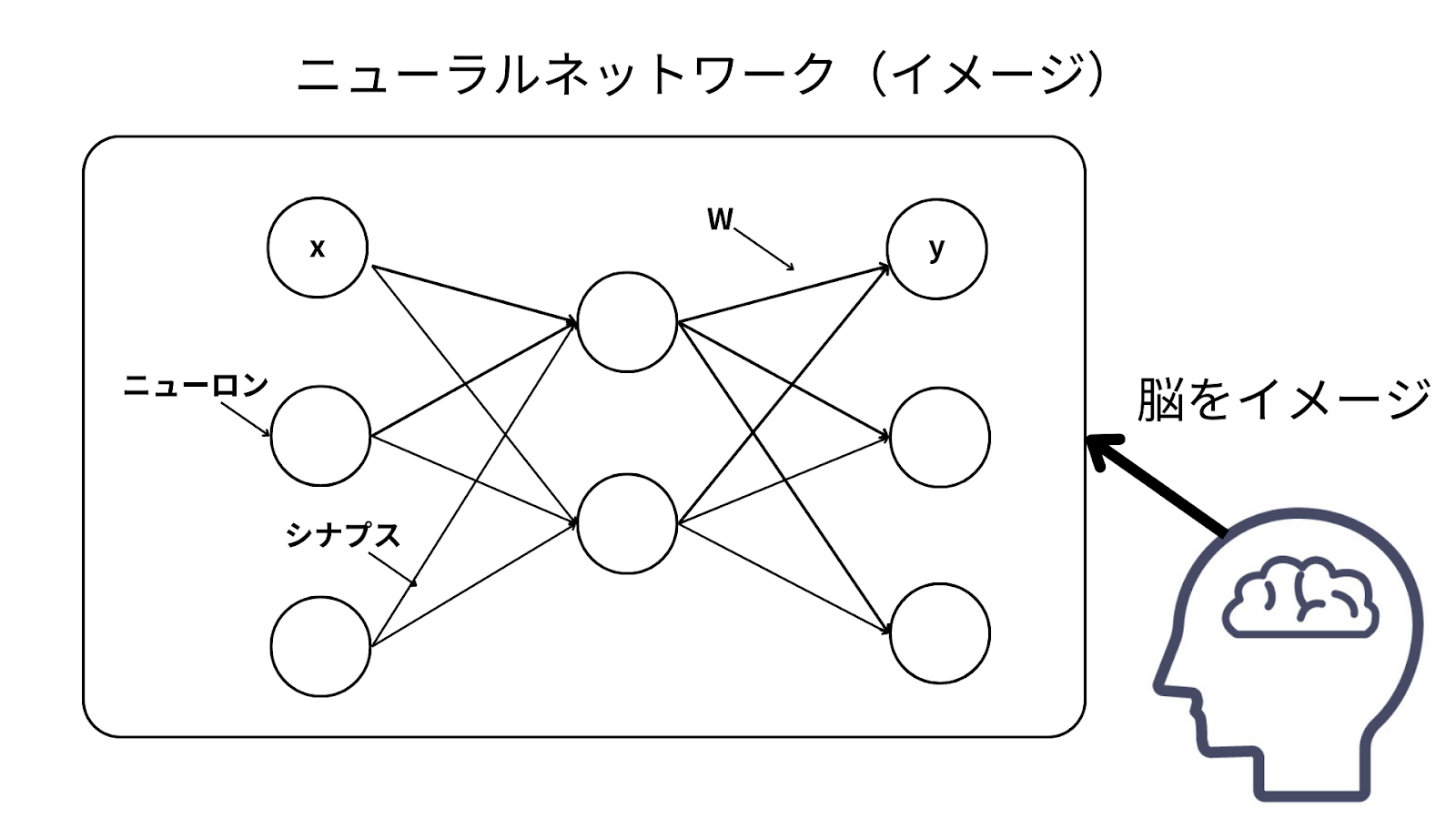
ニューラルネットワークは、1958年にFrank Rosenblatt氏によって考案された「パーセプトロン」が最古のものとなります。パーセプトロンは、当初、何層も構造を重ねると、出力が上手くいかないという課題にぶつかっていました(パーセプトロンの限界)。今回は省略しますが、この課題を解決したからこそ、現在のLLMは存在することができているといっても過言ではありません。
また、最も古典的な例としては、n-gramモデルがあり、これは文章内の単語の順序を統計的に予測するシンプルな方法です。
せっかくなので、このn-gramについて少し解説させていただきます。
n-gramモデルは最も基本的で広く使われている統計的言語モデル(言語の統計的な特性を捉えることを目的としたモデル)の1つです。手法としては、テキストを連続したn個の要素(文字や単語)に分割します。
例えば、下記のような文章があったとします。
私はレストランでチーズケーキを注文しました。チーズケーキがメニューの中で一番美味しそうなケーキでした。
この文章をn-gramで分割してみましょう。
これを”3文字”ずつ分割する「3-gram」を用いると、「私はレ」「はレス」「レスト」といった単語としては破綻してしまっている文字列が多数出てきます。その中でも、最も「ケーキ」という言葉が多く現れるのでこのテキストは「ケーキ」についての内容であるということが推測できます。
このように特徴を抽出することができるのがn-gramモデルです。このようなモデルもまたLMの一種です。
LLM(Large Language Model/大規模言語モデル)
LLMは、その名の通り大規模な言語モデルであり、膨大なテキストデータと数百億から数兆のパラメータを使って学習されています。
代表的なLLMには、OpenAIのChatGPTや、MetaのLlama、GoogleのPaLMがあります。これらのモデルは、幅広いタスク(文章生成、翻訳、要約、質問応答など)に対応できる汎用性があり、多くの業界で活用されています。
LLMの強みは、そのスケールの大きさです。大量のパラメータとデータセットを使うことで、非常に精度の高い結果を出すことができます。また、事前に広範なデータから学習しているため、専門知識がなくても多様なタスクに応用できる点も魅力です。
MetaのLlamaは商用利用無料であり、オープンソースとして展開されています。性能も高いため、多くの企業がこのLlamaを用いて、ソースコードをカスタマイズし、自身のデータを学習させて、オリジナルな活用を行っています。
また、先日公開させていただいたインタビュー記事「【DX推進企業スペシャルインタビュー Part1】注目のAIカンパニー、ELYZAの野口竜司さんに聞く大規模言語モデル(LLM)活用の可能性」で取り上げさせていただいたELYZAからも、Llamaをベースとした日本語言語モデルが公開されています。
SLM(Small Language Model/小規模言語モデル)
一方で、SLMは特定のタスクや分野に特化した小規模な言語モデルです。SLMはLLMに比べてパラメータ数が少なく、軽量であるため、計算リソースが限られた環境でも利用可能です。具体的な数字で比較すると、LLMが数百億~数千億のパラメータを有するのに対し、SLMは数億~数十億程度のパラメータで構成されています。
では、このパラメータが多いとどうなるのでしょうか?
パラメータ数が増加すると、表現力が向上したり、生成能力が向上するなどの様々な効果があります。一方で、計算コストが増大したり、メモリの使用量は増大します。
計算コストの増大、メモリの使用量が増大するという言葉だけで捉えるよりも、「LLMはニューラルネットワークという人間の脳を模した数式モデルが基盤となっている」ということから考えると、「人間の脳」をイメージするとわかりやすいかもしれません。人(脳)が成長していくと、様々なものを処理できるようになっていきます。より流ちょうな言葉が話せるようになったり、様々な言い回しができるようになります。一方で、難しい質問をされたら回答するのに、少し時間を要したり、複雑な回答をする際に、複数の根拠をもとに話していた場合、根拠の明示が難しくなってしまいますよね。幼い頃であれば、聞かれた質問に、0コンマで返答できていたことも、成長していくことで、回答が難しかったりします。
ではパラメータの数が少ないと、いけないのでしょうか?
SLMのようにパラメータが少ない場合は、その分野に特化させることでその分野において高い精度を持つモデルをつくることが可能です。
AIの場合はパラメータ数が増加するほど、多くの計算リソースを必要とします。SLMの場合は、このリソースも少なくて済むため、エネルギー消費を抑えることができます。
あらゆるパターンを認識し、複雑なことを検討することができる頭脳を持つ人間は、LLMに近しい存在と考えられますが、人間の場合は「疲れたときには、休めば再度復活することができる」ということを考えると、AIよりもエネルギー効率は非常に良いですね。
では、どのようなサービスがSLMに該当するのでしょうか?SLMの例としては、Googleの「Gemma」、Microsoft「Phi-3」、日本企業でいえばNTTの「tsuzumi」などが挙げられます。NTT「tsuzumi」は『CXソリューション(顧客応対、コンタクトセンター)、EXソリューション(業務・業界別)、CRX※3ソリューション(IT運用自動化)の分野に特化したソリューション』を提供している様です。
ただし、Googleの「Gemma」も、NTT「tsuzumi」も、LLMとして紹介されている記事もあるため、現時点では、LLMとSLMの境目は少し曖昧であると考えていただくと良いでしょう。
SLMは、特定分野に特化し高い精度を発揮します。また、LLMよりも短時間かつ低コストでトレーニングや運用ができるのが利点です。先ほど挙げた「Gemma」などは、ローカルPC上でも起動させることができます。そのため、特定の分野に特化したソリューションを求める企業にとって、非常に有効な選択肢となります。
最近ではオンデバイスSLM(モバイルで動く生成AI)が登場しました。Googleであれば「Gemini Nano」、Microsoftは「Phi Silica」、Appleは「Apple Intelligence」がそれに当たります。Apple Intelligenceは最新のiPhone16にも搭載されていることから、オンデバイスSLMは、今後さらに発展し、一般消費者の日常において生成AIがさらに一般化するきっかけになると考えられます。
LLMとSLMの導入メリットとデメリット
LLMとSLMはそれぞれ異なる特性を持っており、いずれも導入の際にはメリットとデメリットが存在します。一つひとつ確認していきましょう!
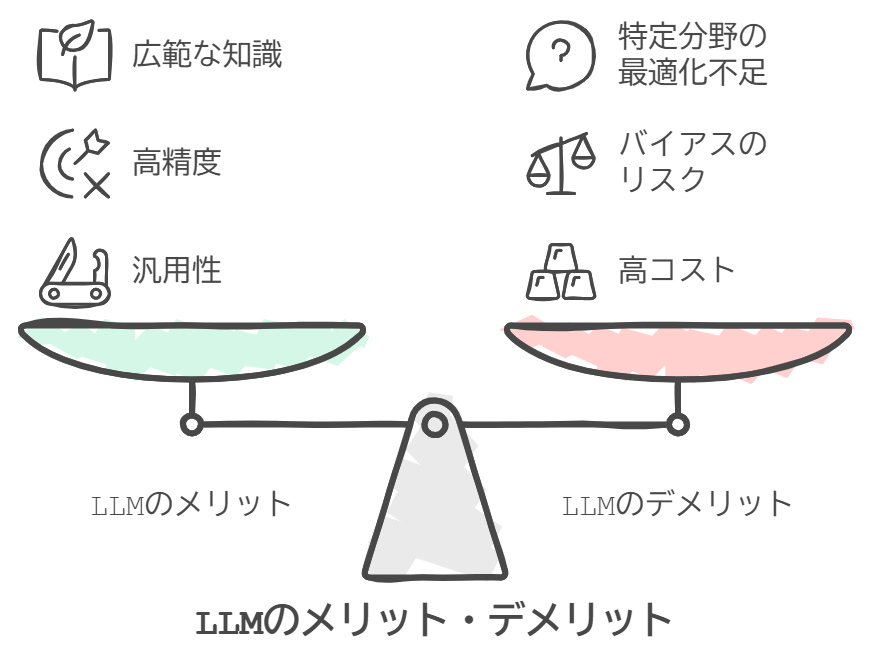
LLMのメリット
LLMのメリットはその汎用性の高さが大きく挙げられます。
1. 汎用性
LLMは事前に大規模なデータセットから学習しているため、幅広いタスクに対応できます。文章生成や自動翻訳、質問応答など、さまざまな用途で活用可能です。
2. 精度
LLMは大量のデータを学習しているため、高度な自然言語処理を必要とするタスクでも高い精度を発揮します。特に、言語理解や対話生成において非常に優れた結果を得られます。
3. 学習した知識の広範なカバー
事前に広範囲のデータから学習しているため、特定の分野に限らず、一般的な知識にも対応できます。これにより、専門家が不要な状況でも高度なタスクをこなすことができます。
LLMのデメリット
汎用性が高く、広範囲のデータから学習していることから、コストがかさんでしまうのがデメリットとして大きくあげられます。
1. コスト
LLMは非常に多くのパラメータを持ち、トレーニングに膨大な計算リソースが必要です。そのため、GPUクラスターや専用のデータセンターが必要となり、運用コストが高くなります。
2. バイアスのリスク
LLMは学習データに依存しているため、データに含まれる偏り(バイアス)がモデルに影響を与えることがあります。このため、特定の社会的、文化的な問題に対して正確な判断ができない場合があります。
3. 特定分野に最適化されていない
LLMは汎用的なモデルであるため、特定の分野においては最適な結果を出せない可能性があります。例えば、医療や法律の分野では、より専門的なモデル(SLM)が必要です。
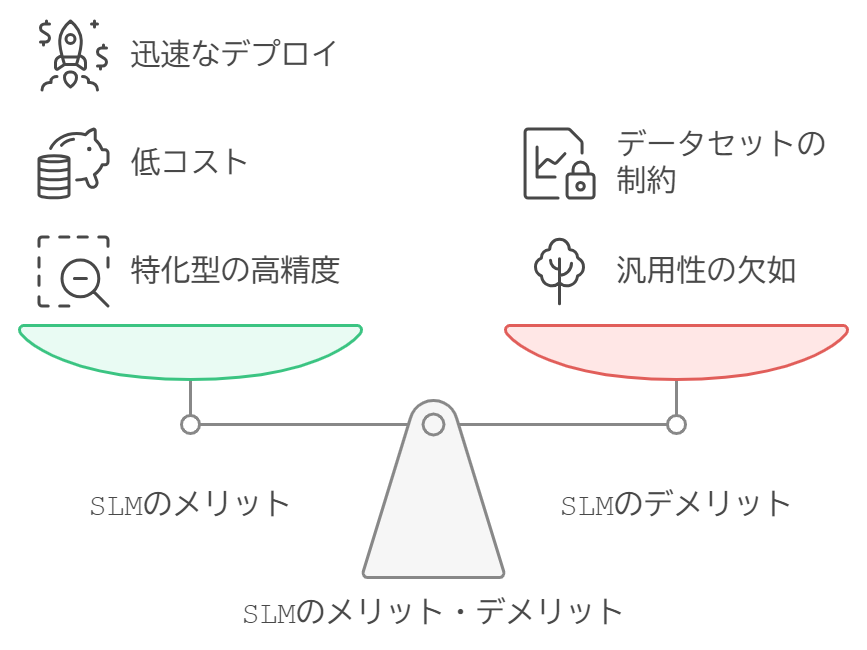
SLMのメリット
SLMのメリットは特化型であることから、希望の回答により早くリーチすることができることが挙げられます。ジェネラリストではなくスペシャリストに聞くことができると考えるとわかりやすいのではないでしょうか。
1. 特化型の高精度
SLMは特定の分野やタスクに特化して設計されているため、該当する分野においてはLLMよりも高い精度を発揮することがあります。特に専門性の高いタスクにおいて効果的です。
2. 低コスト
SLMはパラメータ数が少なく、計算リソースを大幅に節約できます。そのため、トレーニング時間も短く、運用コストも低く抑えられます。
3. 迅速なデプロイ
SLMは比較的小規模であるため、短期間でのトレーニングやデプロイが可能です。これにより、開発サイクルが短縮され、迅速な導入が可能となります。
SLMのデメリット
SLMのデメリットは特化型であることと表裏一体ではあるのですが、汎用的なタスクの処理は困難です。ジェネラリストとスペシャリストで先ほど例に出しましたが、デメリットも同様です。魚のスペシャリストに肉も考慮したフルコースをオーダーするというのはお門違いであり、むしろすべての食材に知見を持つジェネラリストである、総料理長にお願いするのが最適であると考えるとSLMのデメリットもわかりやすいのではないでしょうか。
1. 汎用性の欠如
SLMは特定の分野に特化しているため、汎用的なタスクには対応できません。多様なタスクを処理する必要がある場合、LLMの方が適しています。
2. データセットの制約
特定分野に特化するためには、関連する高品質なデータセットが必要です。きちんとその特定の分野における専門性の高いデータがある程度のボリューム、必要になるということです。これを用意するのが難しい場合、SLMのトレーニングが難航することがあります。
コストの違い:LLMとSLM、どちらを導入すべきか
次に、LLMとSLMのコスト構造について考えます。これらのモデルを開発、導入を検討する際にはトレーニングや運用にかかるコストが大きな判断材料となります。
LLMのコスト
LLMは、数百億から数兆のパラメータを持つため、学習に必要な計算リソースが非常に大きくなります。これにより、専用のGPUクラスターやデータセンターが必要となり、トレーニングには数百万〜数億円規模のコストがかかることもあります。さらに、モデルのサイズが大きいため、運用中もリソース消費が激しく、長期的なコスト負担が大きくなる傾向があります。
SLMのコスト
一方で、SLMはパラメータ数が少ないため、トレーニングに必要な計算リソースも少なく済みます。特定分野に特化しているため、無駄なデータ処理が少なく、効率的な運用が可能です。これにより、トレーニングや運用にかかるコストはLLMよりもはるかに低く抑えられます。
| LLM | SLM | |
| パラメータ数 | 数百億~数兆 | 数億~数十億 |
| 計算リソース | 大きい | 比較的少ない |
| 学習領域 | 汎用的 | 特定の分野に特化 |
| コスト負担 | 高 | 低 |
LLMとSLMの具体的なサービス事例
ここまで、その概要、メリット・デメリット、そのコスト構造を見てきました。ではその内容を踏まえて、LLMとSLMの具体的なサービスについて見ていきたいと思います。ここでは、主要なLLMおよびSLMの例と、それらの違いについて解説します。
LLMの主要なサービス例
– GPTシリーズ(OpenAI)

最近では、o-1 previewやo1-mini、そして「Advanced Voice」機能が有料会員に対してリリースされました。「Advanced Voice」機能を使うと、AIと(少しタイムラグは発生するものの)割と自然な掛け合いをすることができるので、漫才に活用されている方もいらっしゃいました。
https://x.com/i3design_jp/status/1839468202293895263
また、o-1 previewだけではなく、これまで出てきた4oやGPT3.5等のGPTシリーズは、数千億〜数兆のパラメータを持つ大規模なモデルであり、文章生成、画像生成など多様なタスクに対応可能です。特に、文章生成やチャットボットの分野で広く活用されています。
簡易的な操作(文字入力)だけで誰もが生成AIを活用できる状態にした、というのが非常に画期的でした。
– PaLM(Google)

2022年4月に発表されたGoogleが開発した大規模言語モデルです。PaLMも数兆のパラメータ(※)を持つ大規模モデルであり、文章生成、翻訳、質問応答など、さまざまなタスクで優れた性能を発揮しています。
SLMの主要なサービス例
– Gemma

2024年2月にGoogleから発表された大規模言語モデルです。このモデルは、オープンソースであるため、誰もが使用することが可能です。また、GoogleのマルチモーダルAI(※)「Gemini」の技術を基にしております。ノートパソコンやデスクトップPCでも実行が可能なほど軽量に設計されています。
マルチモーダルAIとは
テキスト、音声、画像、動画などといった複数の異なる種類のデータを同時に処理し、統合的に理解する能力を持つ人工知能のことです。(↔シングルモーダルAI)
詳しくはこちらの記事を参照ください。▼
https://www.softbank.jp/biz/solutions/generative-ai/ai-glossary/multimodal-ai/
– Phi-3

2024年4月にMicrosoftがリリースした小規模言語モデルであり、GPT-3.5といった大規模モデルと同等の性能を発揮するといわれています。Phi-3はリソース効率が高く、iPhone 14上での実行が可能であり、わずか1.8GBのメモリで動作することができます。
超お手軽!Google Notebook LMを使って、オリジナルの辞書をつくってみよう!
ここまでLLMやSLMについて解説してきましたが、実際に自分専用にカスタマイズしたLMを使ってみると少しイメージが湧いてきやすいと思うので、今回は、非常に手軽に始められるGoogle NotebookLMを紹介したいと思います。
NotebookLMは、Gemini 1.5 Proが搭載されたモデルであり、これを活用すると、手軽に自分だけの辞書をつくることができます。「自分だけの辞書とは何ぞや」と思われる方もいらっしゃると思いますが、是非、それはここから下の文章を読んで体感していただければと思います。
コーディングなど、専門的な知識を全く必要としないので、簡易版のRAG(※)と認識してもいいでしょう。
(※)RAGとは
RAGは、Retrieval-Augmented Generationの略称です。日本語表記としては「検索拡張生成」と訳されます。LLMの性能を向上させるAIフレームワークであり、よりユーザーの要望に合わせてカスタマイズさせたものです。
本記事を展開しているアイスリーデザインの社内でも、RAGを開発しているのですが、そのRAGにおいては社内情報を読み込ませて、福利厚生や社内規定に関する質問を投げかけることでAIが社内情報から検索し回答を自動で生成されるようにしています。このように特定の情報を読み込ませて、適切な回答を自動で検索して、AIに回答してもらうような手法をRAGといいます。
Experimentalと記載があるようにまだ「実験中」であることからか、現在はGmailアドレスを持っていれば無料で使うことができます。(2024年9月27日現在)
ではここから、NotebookLMの使い方を軽く紹介いたします。
NotebookLM
https://notebooklm.google.com/
上記URLからNotebookLMに自身のGmailアカウントでログインすると下記のような画面が開かれるので「新しいノートブック」をクリックしましょう!
すると下記のような画面が現れます。

この「ソースを追加」の画面に、つくりたい「自分だけの辞書」の元となるデータを入力します。PDF、Google Document、Youtubeリンク。ありとあらゆるものをアップロードすることが可能です。
今回は、PDFをアップロードするパターンと最近(2024年9月26日)実装された機能、Youtubeリンクの挿入パターンの2種類で試したいと思います!
ソース:PDFの場合
弊社が発行している「Webアクセシビリティチェックリスト」を試しに入れてみようと思います。
https://www.i3design.jp/download/webaccessibilitychecklist
ここからPDFをダウンロードしたら、ソースをアップロードにドラッグ&ドロップします。すると数分経過した後、下記のような画面が出てきたら、辞書の準備が終了です。
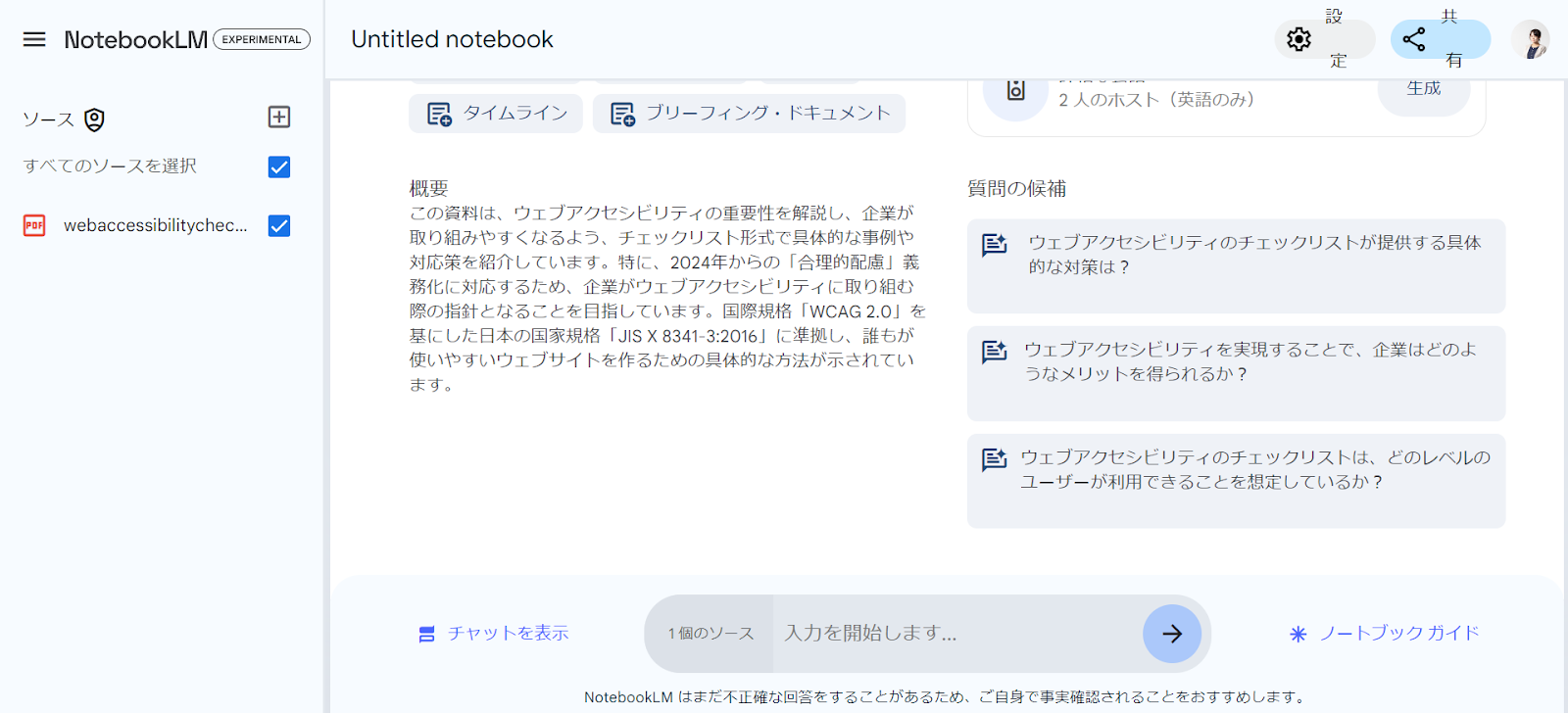
このようにPDFから情報を読み込み、概要や質問の候補が出力されます。
質問をクリックすると何とこのデータを検索して、情報をピックアップしてくれます。
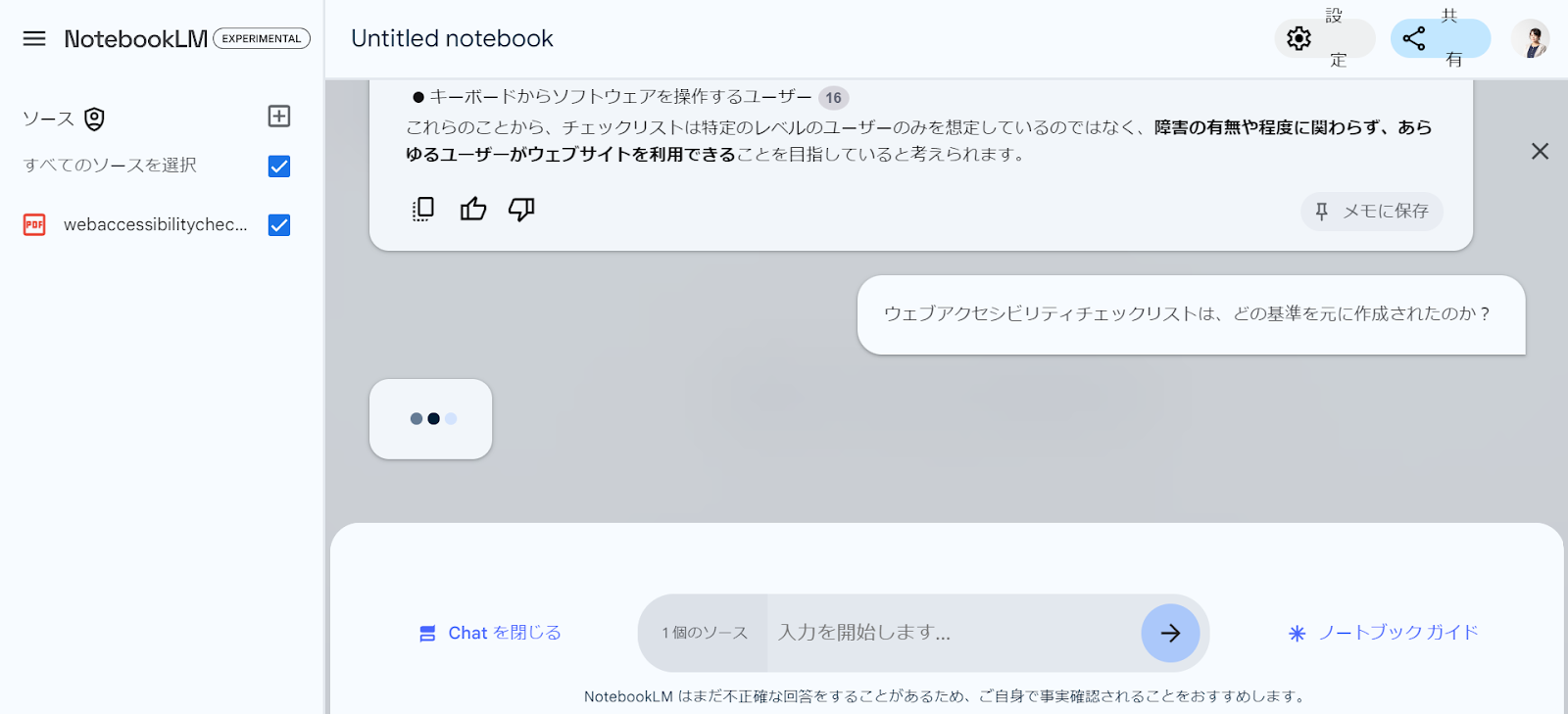
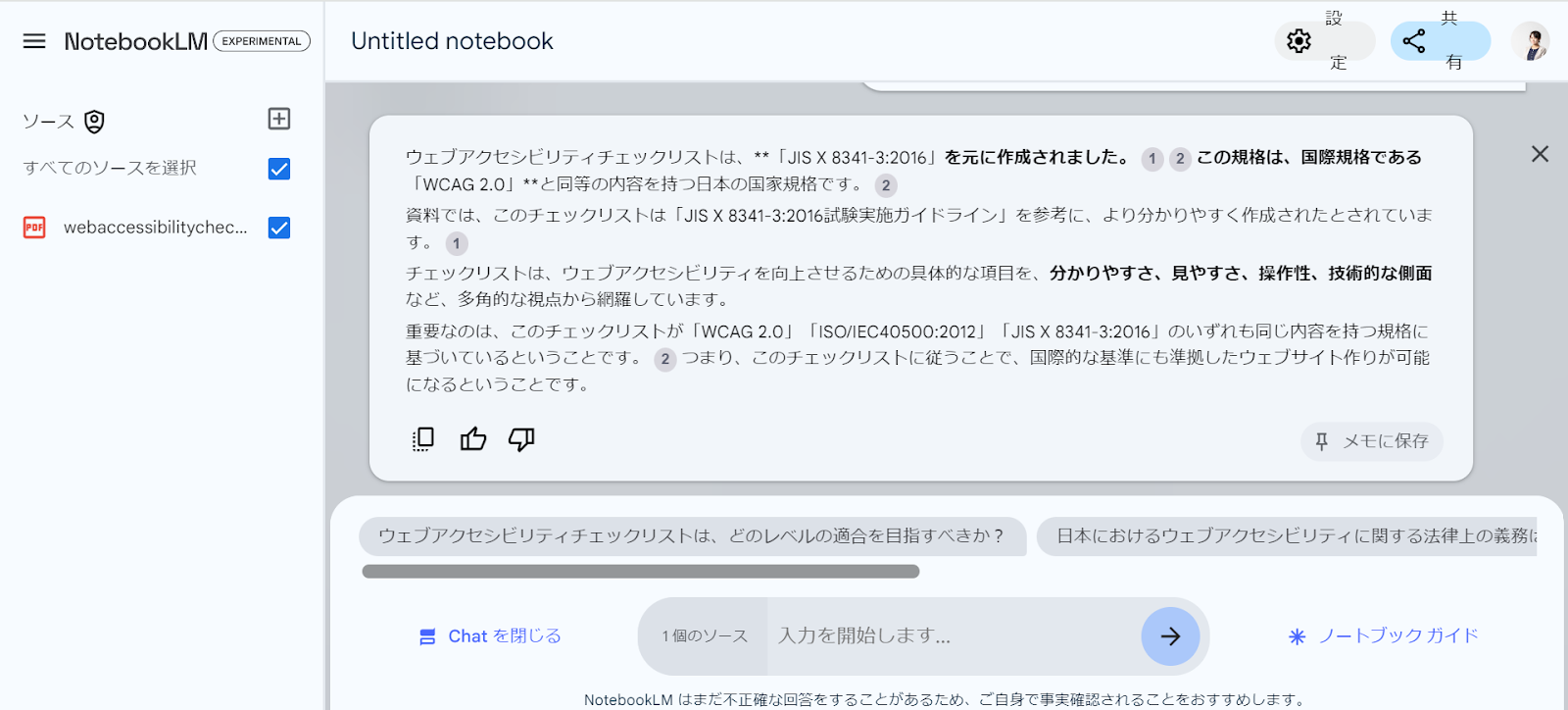
このように知りたかった情報をAIを用いて探し出すことができるのです。
ソース:Youtubeの場合
今回は、デジタル庁の年次活動報告をNotebookのソースとしてアップロードを行いたいと思います。
出典:「デジタル庁|年次活動報告 2024年9月」(デジタル庁)
先ほど出てきたソースの追加を下にスクロールすると、リンクというボックスの中に、Youtubeがあるので、クリックしましょう。

すると、YoutubeのURLを入力する画面が現れるので、リンクを入力し、挿入ボタンを押します。
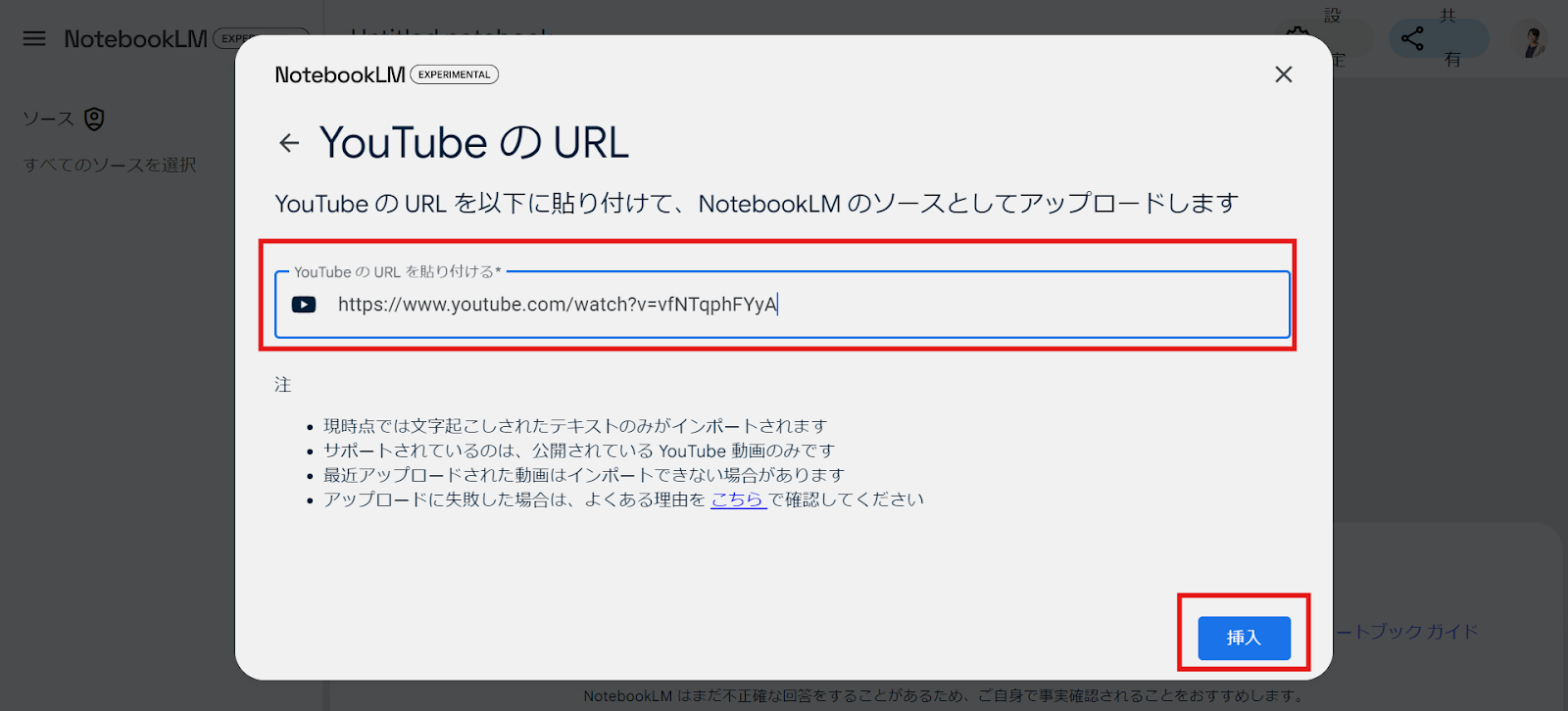
すると、ものの数秒で概要と、質問の候補が生成されました!

早速質問を投げかけてみましょう!
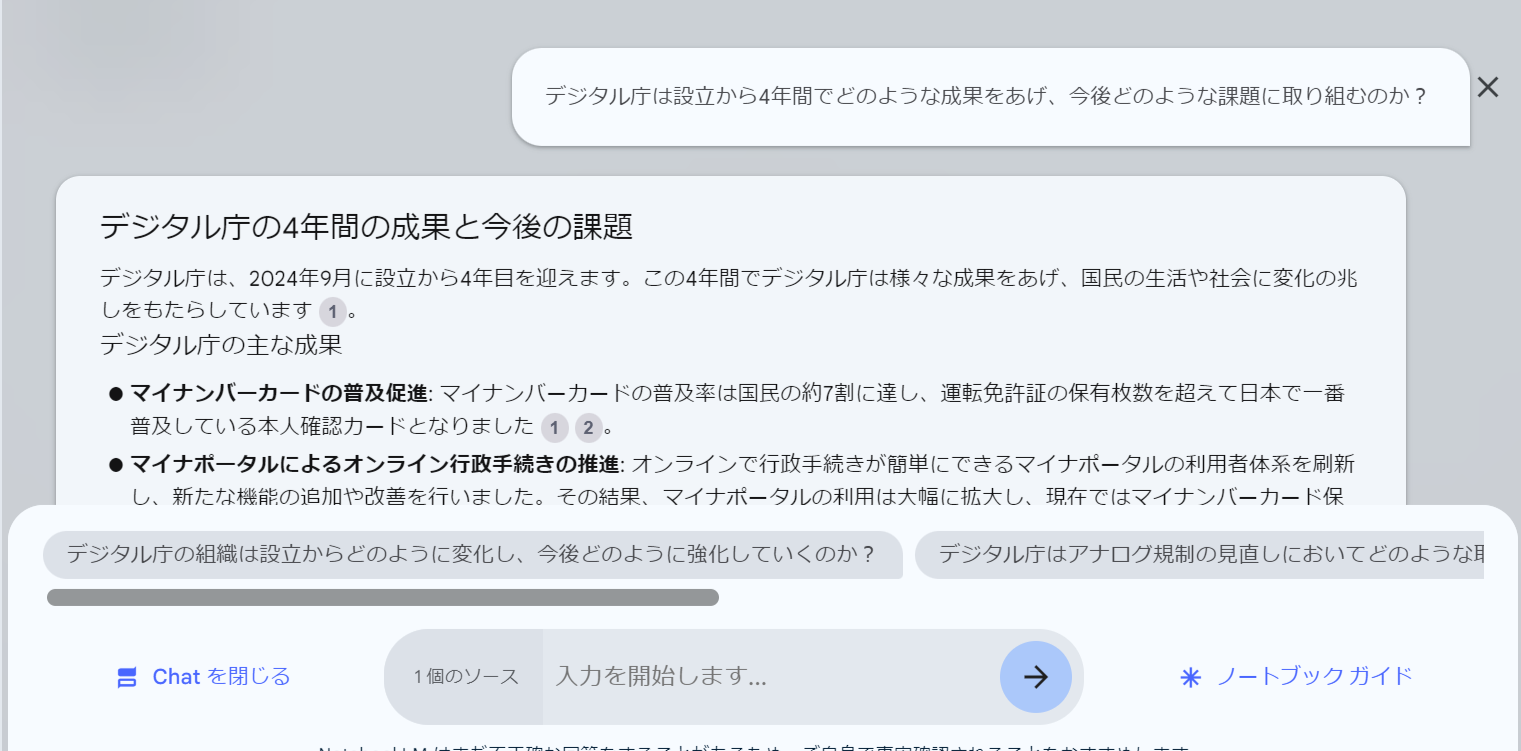
このように知りたい情報を即座に見ることができます。
ただし、あくまで、デジタル庁のYoutubeを読み込んだNotebookLMによって加工されたデータとなるので、NotebookLMの最下部にも注釈があるように扱いには注意が必要です。(NotebookLM はまだ不正確な回答をすることがあるため、ご自身で事実確認されることをおすすめします。)


なお、回答の最下部にある「メモに保存」をクリックすると、メモとして保存することができ、知りたい情報をそのNotebookのトップ画面に常に表示させておくことが可能となります。


また、左側にあるソースをクリックすると、文字起こしも見ることができます。
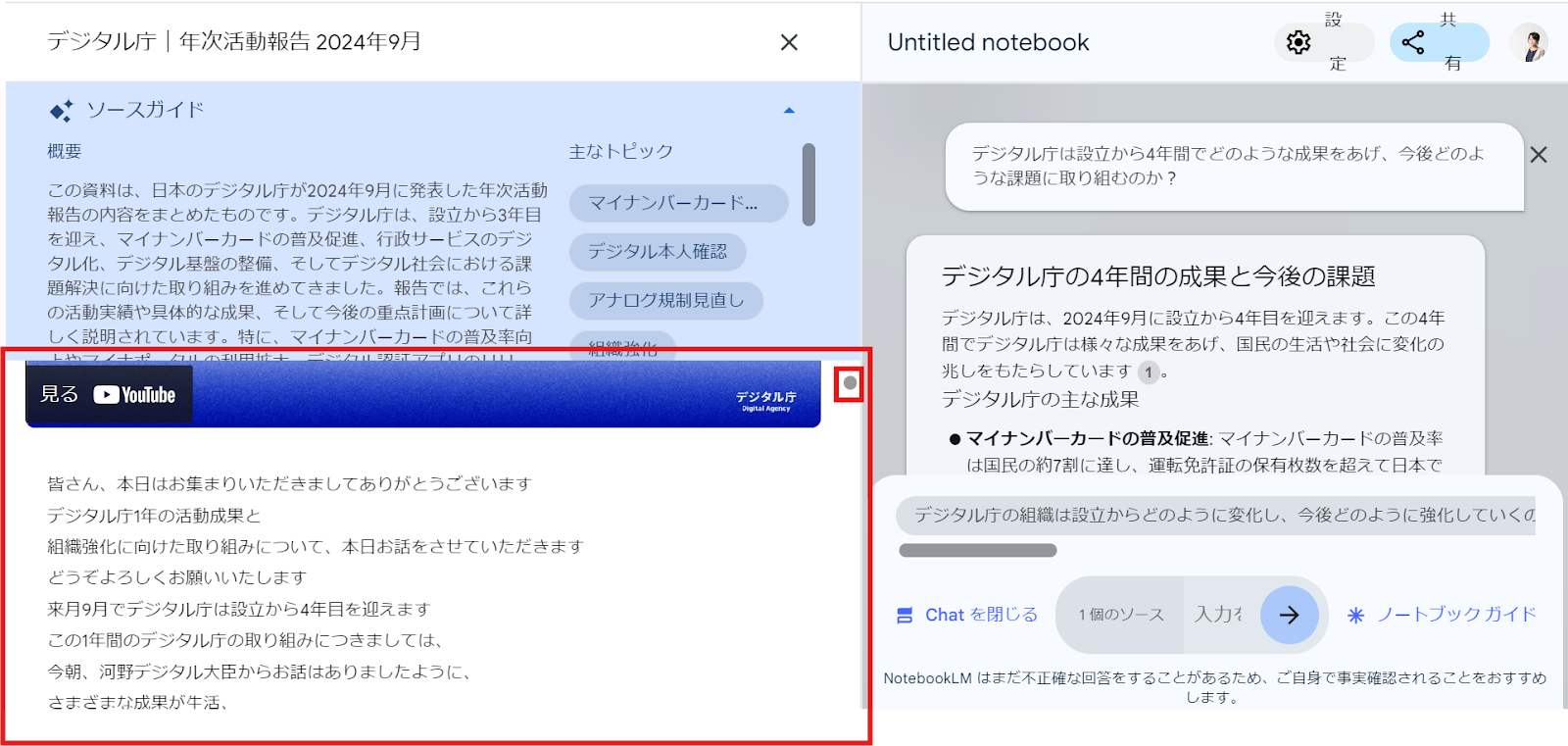
左下の赤枠で囲まれているのが、文字起こしエリアで、右側のボタンをスクロールすることで文字起こし全体を見ることができます。
そのため、Notebook LMを使えば、下記のようなメリットを享受することができます。
- 概要だけざっくりと知ることができる
- 知りたい情報をすぐに質問して答えが返ってくる
- その整合性を文字起こしデータで確認することできる
かなり使い勝手がいいですね。
ちなみに、この「Untitled Notebook」のところの名前を変更すると非常にわかりやすくなります。例えば、名称を「デジタル庁」に変えてみましょう。そして、ソースの隣のマークを押せば、複数のソースを同じNotebookの中で見ることができるようになります。
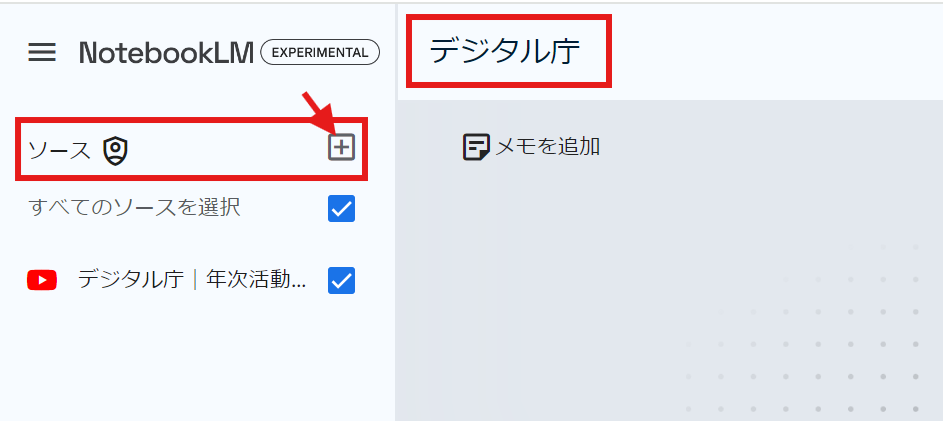
もちろんまだ、開発中であるということから、前述した通り、不正確な情報を出力してしまう可能性もあるようですが、そこは適宜事実確認をしながら使用されることをおすすめします。
NotebookLMの情報セキュリティについて
また、プライバシーとしては下記のような記載がありました。(日本語訳はGoogle Translateを使用)Notebookのトレーニング(学習)には、ソースのデータは使われないが、人間がレビューすることはあるようなので、公的になっていない機密情報などは、送信しないことをお勧めします。
一方で、Googleとの契約において、Google DriveにWorkspaceまたはWorkspace for Educationの利用が適用されている企業の場合はそのレビューが行われないとのことなので、Google Driveにアップロードしているのと変わらないため、Driveにアップロードしている情報をこちらのNotebookLMに挿入するのも問題ないようです。
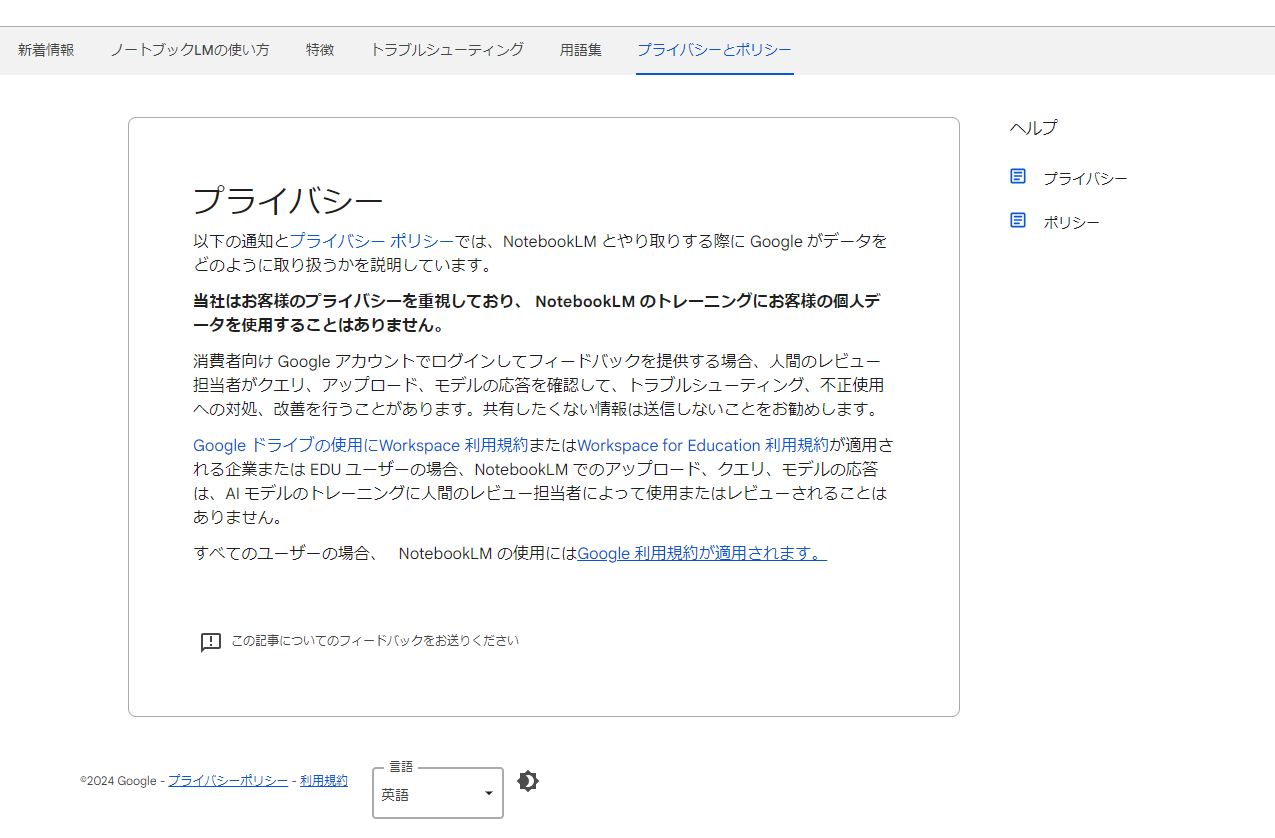
業務上使用している資料など、機密性の高い情報を扱いたいと思われた際には、自身のアカウントの利用規約がどうなっているかを確認した上でアップロードする情報は検討しましょう。(また、こちらはあくまで、2024年10月1日時点での情報になります。最新のプライバシーポリシーを確認してください。)
また、公的に公開されているものであれば気兼ねなく、お手軽に始めることができるので、まずは自身が読みたい資料やYoutubeから、是非、始めてみてください。
まとめ
LLMとSLMは、それぞれ異なる特性を持つ言語モデルであり、用途に応じた選択が重要です。LLMは汎用性が高く、幅広いタスクに対応できますが、コストや計算リソースの負担が大きくなります。一方、SLMは特定分野に特化しており、コスト効率が良い反面、汎用性に欠ける場合があります。企業がAI技術を導入する際には、目的に応じて適切なモデルを選択し、コストと効果を最大化することが求められます。
また、Notebook LMは自分専用の辞書をつくることのできる便利なツールです。巷で名前の聞いたRAGとはどういう優れたものなのかを体感するためにも、そして、自分自身の知識収集などにも有効に使える手法です。是非、一度試してみてはいかがでしょうか?
AIを活用して業務効率を上げたい、自社特有の情報を理解したAIを全社で使っていきたいが、とりあえず相談してみたいという方は是非、下記からお問い合わせください。
本メディアサイトを運営するアイスリーデザインでは、特徴量エンジニアリングを用いて、UIデザインと画面レイアウトのアウトプットをコントロールする技術(プレスリリース)を開発いたしました。一般的なLLMではなかなか自社特有の特徴を捉えた画像生成は難易度が高い中で、特徴量エンジニアリングを用いることによって、出力をカスタマイズすることに成功しました。また、前述したようなリソースの問題も、通常のLLMと比べて大幅に削減することに成功しています。
特徴量エンジニアリングについて知りたい方は、こちらの記事「特徴量エンジニアリングとは?需要予測AIや画像生成AIの精度を上げる手法について初心者向けに解説!」をご覧ください。
本開発の詳しい内容を知りたい方は「LLMについてのin-Pocketの記事を読みました」とコメントを一言添えていただき、下記からぜひ一度お問い合わせください。